
What are iterators?
SQL Server breaks queries down into a set of fundamental building blocks that we call operators or iterators. Each iterator implements a single basic operation such as scanning data from a table, updating data in a table, filtering or aggregating data, or joining two data sets. In all, there are a few dozen such primitive iterators. Iterators may have one, two, or more children and can be combined into trees which we call query plans. By building appropriate query plans, we can execute any SQL statement. In practice, there are frequently many valid query plans for a given statement. The query optimizer’s job is to find the best (e.g., the cheapest (in costs)) query plan for a given statement.
How do iterator’s work?
An iterator reads input rows either from a data source such as a table or from its children (if it has any) and produces output rows which it returns to its parent. The output rows that an iterator produces depend on the operation that the iterator performs.
All iterators implement the same set of core methods. For example, the Open method tells an iterator to prepare to produce output rows while the GetRow method requests that an iterator produce a new output row. Because all iterators implement the same methods, iterators are independent of one another. That is, an iterator does not need specialized knowledge of its children (if any) or parent. Consequently, iterators can be easily combined in many different ways and into many different query plans.
When SQL Server executes a query plan, control flows down the tree. That is, we call the methods Open and GetRow on the iterator at the root of the query plan and these methods propagate down through the tree to the leaf iterators. Data flows or more accurately is pulled up the tree when one iterator calls another iterator’s GetRow method.
A simple example Consider the following query:
select count(*) from dbo.t
The simplest way to execute this query is to scan each row in table [t] and count the rows. SQL Server uses two iterators to achieve this result: one to scan the rows in [t] and another to count them:
<– count(*) <– Scan [t]
To execute this query plan, we call Open on the count(*) iterator. The count(*) iterator performs the following tasks in Open:
- it calls Open on the scan iterator which readies the scan to produce rows;
- it calls GetRow repeatedly on the scan, counting the rows returned, and stopping only when GetRow returns that it has reached the end of the scan; and
- it calls Close on the scan iterator to indicate that we are done.
Thus, by the time the count(*) iterator returns from Open, it has already calculated the number of rows in [t]. To complete execution we call GetRow on the count(*) and it returns this result. (Technically, we call GetRow on the count(*) one more time since we do not know that count(*) produces only a single row until we try. The second GetRow call returns that we have reached the end of the result set.)
Note that the count(*) iterator does not care or need to know that it is counting rows from a scan; it will count rows from any sub-tree we put below it regardless of how simple or complex the sub-tree may be.
Finally, the scan is implemented using the aptly named table scan iterator while the count(*) operation is actually implemented using the stream aggregate iterator. I’ll delve into more detail about many of the different iterators supported by SQL Server in future posts.
create table dbo.t
(
id int identity
);
insert into dbo.t default values;
go 10
select count(1) cnt from dbo.t;
The Execution Plan is read from right to left. In SQL Server 2025 the Operator values are exactly the same. The Operator Costs are based on Nick’s machine (probably a Pentium processor and an spinning hard disk, soft disks were 5.25″ or 3.5″ floppy/cd drives. Query Costs are meaningless now, but still used by the Optimizer to decide which access path is chosen to bring up the data. The modernization of hardware is not taken into account.
Question: Will “AI” soon be able to present server customized values for these Operators?
So when the SQL Server Engine starts it probes the hardware settings, creates meaningful cost values an uses the in the Execution Plans, so Execution Plans differ on different machine based on the ‘hardware’ settings.


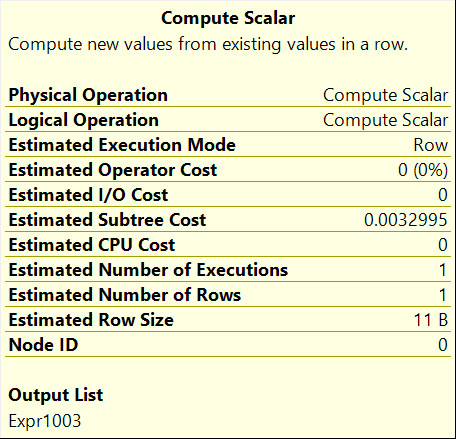
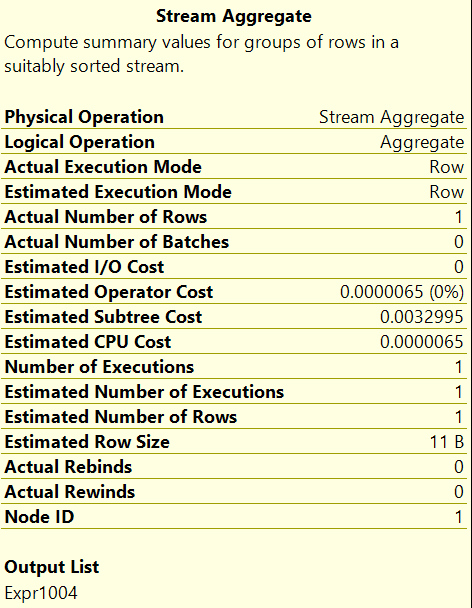
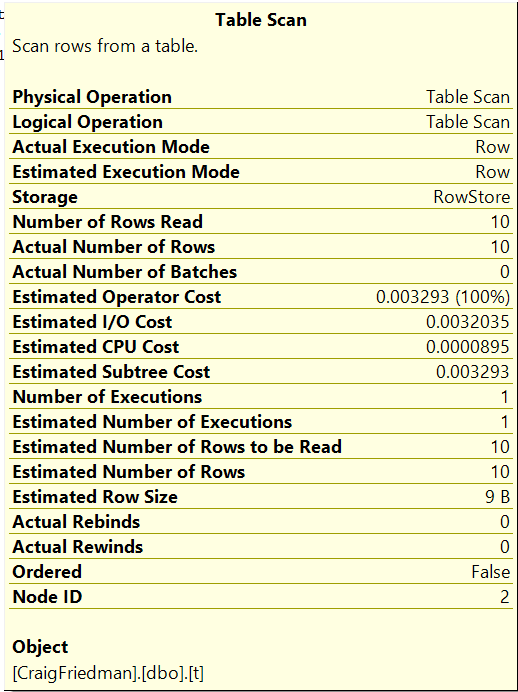
They, Operator Costs, all were and are still based on Nick’s machine. Read (t) is Twitter.

“The Operator Cost value for a Key Lookup operator in a Nested Loop join (or any other context) is calculated by the SQL Server query optimizer based on several factors, including:
- Number of Rows: The estimated number of rows that will be processed by the Key Lookup operation.
- Index Properties: Whether the index used for the lookup is unique or non-unique.
- Costing Model: SQL Server uses a costing model to estimate CPU and I/O costs.Historically, in older versions like SQL Server 2000, the cost of a Key Lookup was often assigned a base value that depended on whether the index was unique or not:
- For a unique index, the cost might be assigned a lower value (e.g., 0.0033 cost units per row).
- For a non-unique index, the cost might be slightly higher (e.g., 0.0053 cost units per row).”